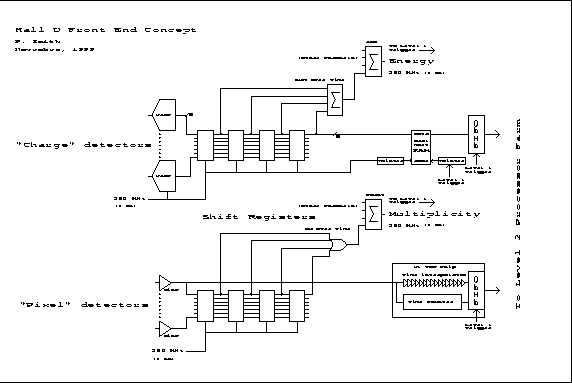
A possible pipelined Trigger/DAQ architecture is shown in Figure 2. Detectors
which measure charge (calorimeters, dE/dX) are digitized by 250 ![]() MHz flash ADCs
(FADC). The data pass through a shift register thus making available a time
window. Successive samples within this time window are added together. This is
equivalent to the gate width in a conventional charge sensitive ADC. Multiple
channels are added together to form an energy sum. These adders are pipelined
at the same 250
MHz flash ADCs
(FADC). The data pass through a shift register thus making available a time
window. Successive samples within this time window are added together. This is
equivalent to the gate width in a conventional charge sensitive ADC. Multiple
channels are added together to form an energy sum. These adders are pipelined
at the same 250 ![]() MHz rate, giving an energy measurement every 4 nS for use in
the Level 1 trigger.
MHz rate, giving an energy measurement every 4 nS for use in
the Level 1 trigger.
After passing through the shift register, the data are stored in a RAM. 16K locations would store 64 uS worth of time information. If this RAM has 2 ports, the data can be read out while the FADCs continue to run, making the front end electronics completely deadtimeless.
Upon receipt of a Level 1 trigger, a pointer address is calculated and data are read from the FADC dual port RAMs and passed to Level 2 hardware/software. To achieve a practical data transfer rate, the zeros must be suppressed in hardware at this point.
The shift registers, adders, and dual port RAM would be implemented as an application specific IC (ASIC) or possibly in a programmable gate array (PGA). Adders and memory lead to extremely regular structures and are efficiently implemented in an IC.
``Pixel'' detectors such as drift chambers would have a similar shift register for the Level 1 trigger. Stages of the shift register would be ORed to provide a time window and counted by adders pipelined at 250 MHz, thus giving a multiplicity value every 4 nS for use in the Level 1 trigger. A momentum cut could be implemented by looking at the outer layers of detectors in the solenoid since low momentum tracks ``curl up'' in the magnetic field and don't reach the outer layers. Forming tracks or at least track segments is also a possibility.
Before discussing CODA, one area that has to be studied further for Hall D is the processing required to reduce the tremendous amount of data generated by the FADC channels. This data must be analyzed and reduced to a few words per event. Many questions remain to be answered. What are the algorithms involved? How much processing does this require? What type of processor is best suited to this task? How do we handled the flow control? For the following discussion, we make the conservative assumption that the output of the FADC reduction results in about 12 bytes/channel. If sufficient reduction can't be achieved, then the data volume could become a problem for both the VME backplane and the communication network from ROCs to EBs.