--SRC Index
I'm not saying I don't believe you, but I don't.
After years of "get the high-x cross section right", John has lowered his demands to "just explain to me why they're wrong in a satisfactory way". And saying, "dude, just trust me on this", is somehow not a good enough explanation. Shrug.
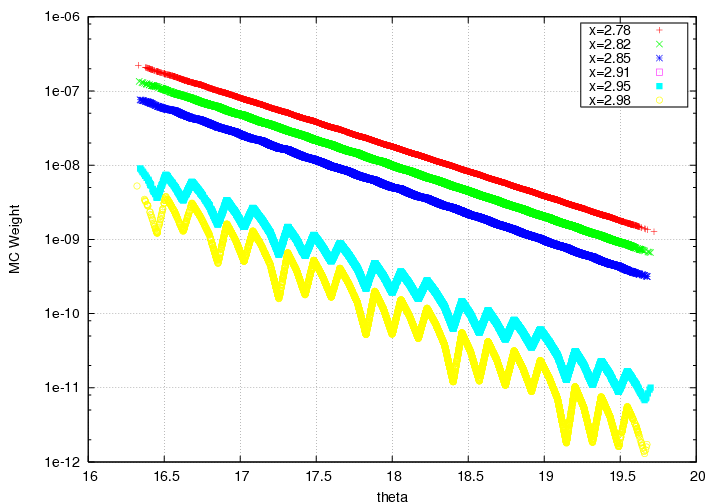
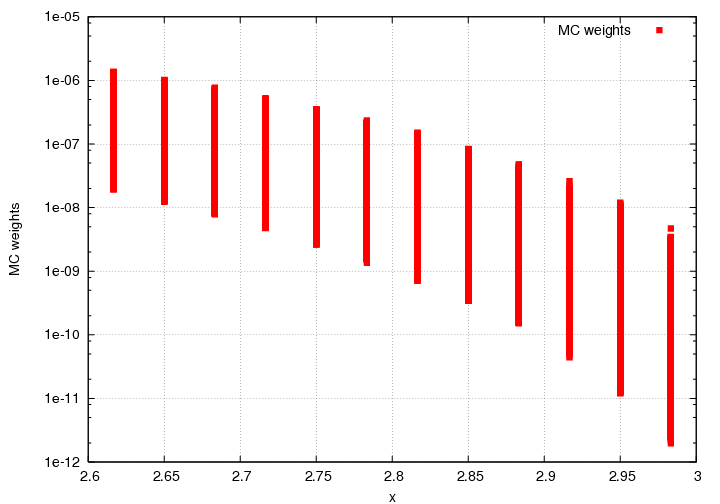
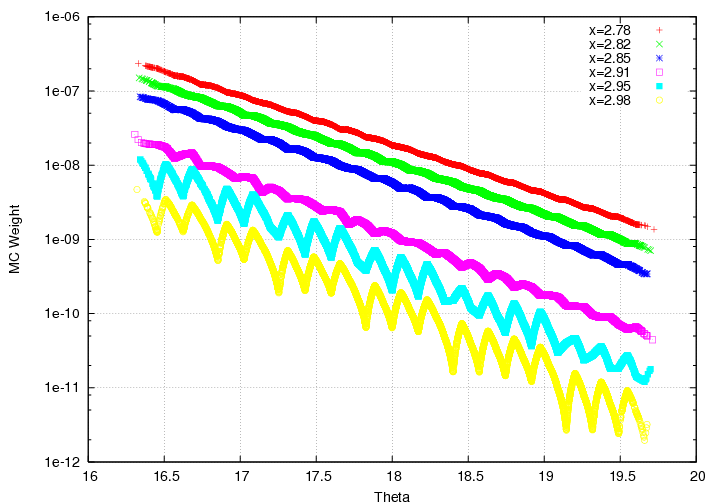
Reminder: The bin-centering in x is completely turned off, we're only bin-centering in theta. This means, that if we look at MC weights as a function of x (so, Y_MC, the equivalent of how bin-centering corrections are done), it looks like this (where the lines correspond to x bins in our big model lookup table at a range of theta values):
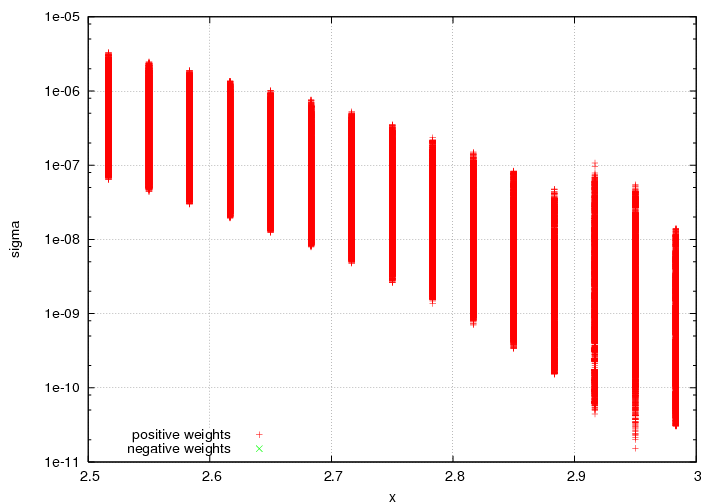
I fully admit there's something rotten in the state of Denmark. For example, if I look at the model look-up table (one that I use for both MC weights, and the final cross section value at the central theta for each of my x-bins), and then compare to my extrapolated values that go into my cross section, it's not okay, and I will try to figure out why:
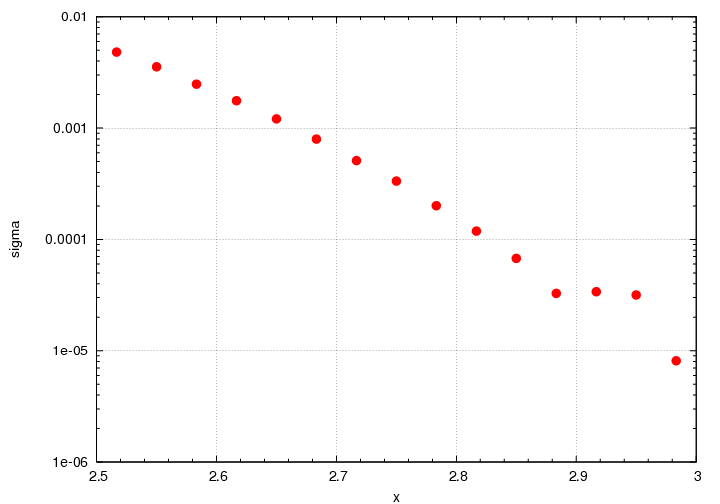
If we look at the plot of Y_MC, we notice that there's something clearly not quite right about the last few points:
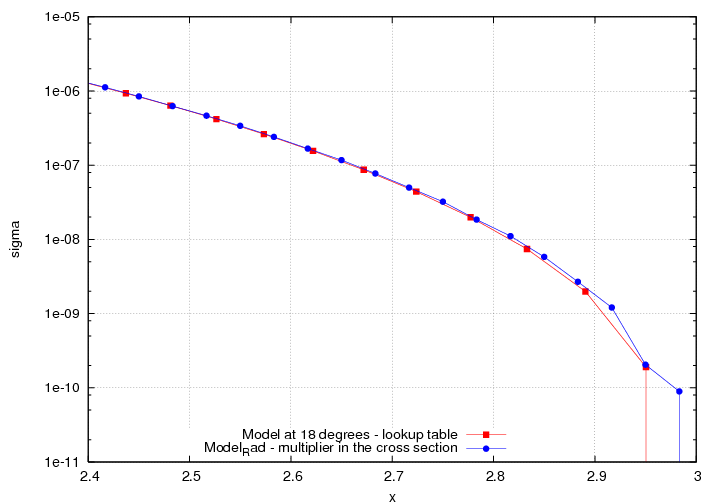
One of the reasons for that, is that in order to avoid negative weights, we anchor the extrapolation of the cross section in the following way: if the x of the event falls after the last x-value in the lookup table for which there's a defined answer, we do a fit between *that* value and 0 at x=3. Now, that x-value is low enough, that there can be as many as 3 bins after it, meaning, they'll all get the same MC weight and look the same (or close). For example, here is a plot of the model (lookup table vs x) for a few values of theta:
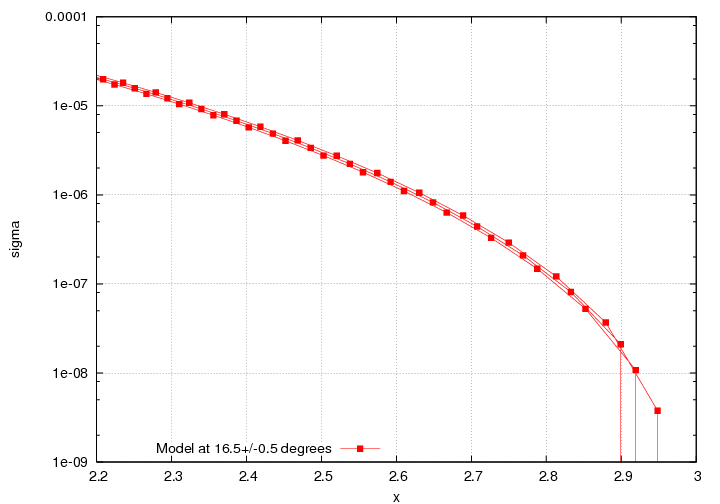
Maybe found a little problem (Nov 16th, 2010)
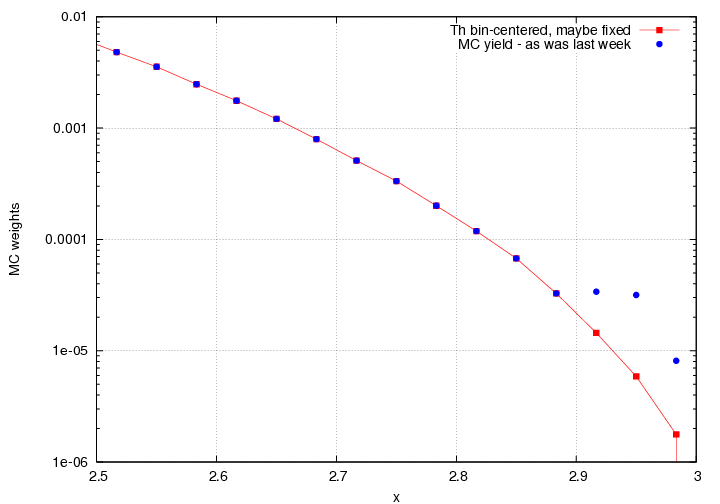
I *thought* that for the last existing non-zero value in the lookup table, the code interpolated between that value and 0 at x=3, but it turns out, it took a couple of bin steps back, which is probably too many, resulting kind of a slow fall off, and probably why the MC yield looked funky. Here's a "fixed" version (however, there's no theta-bincentering going on now, since it's easier to find problems this way, so it's just weighted with Model_rad at the central x, theta of the bin).
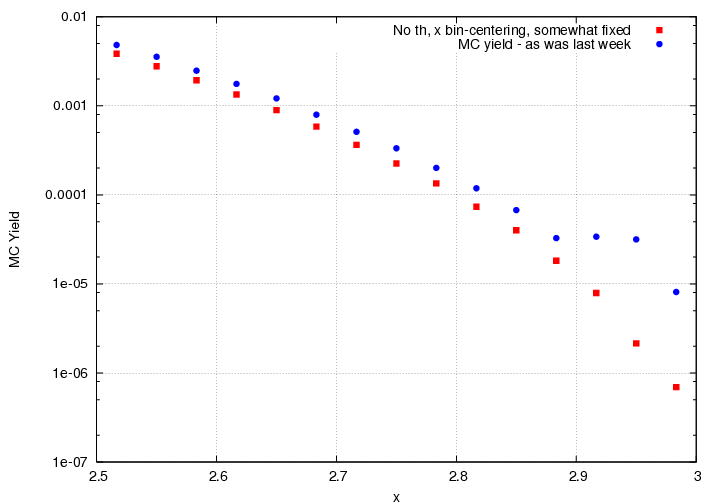
And here's what it looks like if I turn the theta-bincentering back on.
What's different - The problem is that the code wasn't doing what was described above.
I hope this is somewhat clear: I have an event in x, theta. I find the 4 closest x,theta points in the look up table, and I look at them
by pairs: (th1, x1) && (th1, x2); (th2, x1) && (th2, x2). Taking the first pair, if the sigma_rad for th1,x2 is zero,
what I *was* doing (and didn't realize), was incrementing x1--, even if sigma_rad(th1,x1) was >0. And then
interpolated between sigma_rad (th1,x1-2bins) and sigma_rad(th1,x=3)=0. So, I moved 2 bins back in x when I
didn't need to. I "fixed" it to stop doing that if the lookup table value is not 0.
And the weights from MC:
Finally, the radiated model we use as weights for the MC (theta=17.9427), log and lin at the end:
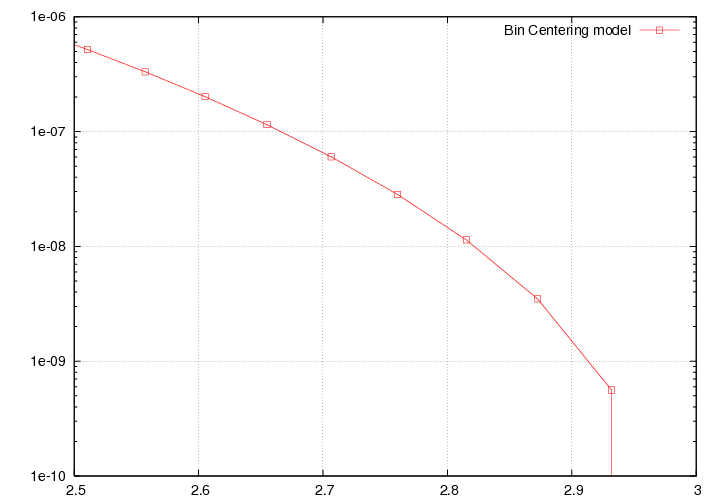
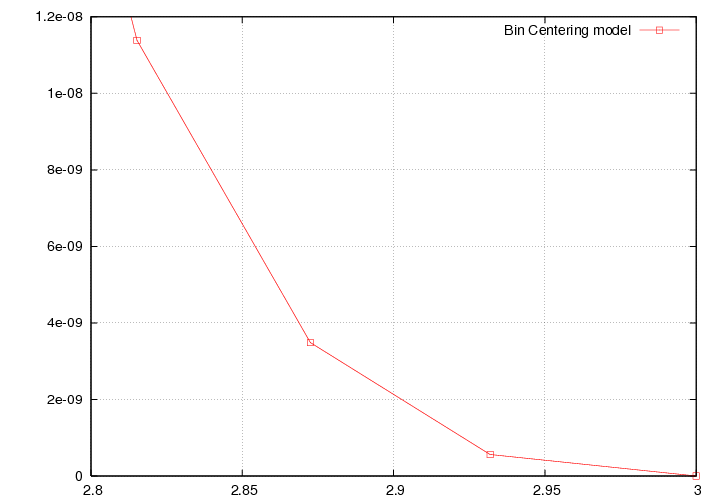
Looking in x bins (so, fixed values of x) at the interpolated model (grabbed out of the look up table) vs theta. The highest 2 xvalues go between last known point and 0 at x=3.
Try switching to exponential interpolation
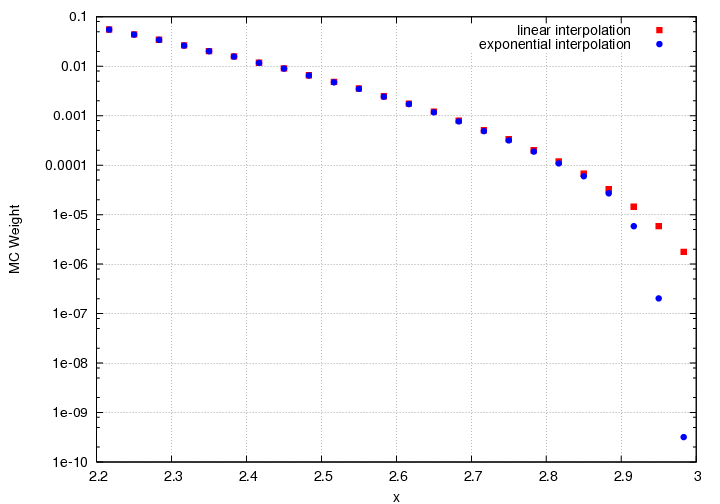
Weights from using exponential interpolation.