What is CODA?
The CODA software is a toolkit from which data acquisition systems may be constructed. In order for the toolkit to make any sense a the model for data acquisition has to be understood. The data acquisition system is constructed from modular components (usually programs) which are spread over a network of processors. The primary function of each component is to take data from some input source(s), manipulate it and pass it to an output. The components are distributed and interconnected in such a way that the overall result is that data from a detector is collected and archived on long term storage media. The components are acted upon by a group of utilities which perform such functions as configuration, data flow control and monitoring the "health" of the system.
The CODA system is currently under continuous development as the needs of experimenters evolve. The first virson of CODA reached stability with version 1.5 which is supported on HP HP-UX, Sun Solaris and DEC ULTRIX machines.
Author's note Although ULTRIX versions of CODA 1.5 binaries still exist ULTRIX was taken out of service at Jefferson lab in fall 1998. We now have no operational ULTRIX machines to perform bug fixes etc at Jefferson lab. CODA versions above 2.x were never tested on ULTRIX.
Version 2.0 of CODA was developed between 1994 and 1998 to meet the needs of the CLAS detector. Version 2.1 was released late in 1998 for general use at Jefferson lab where it has almost completely replaced CODA 1.5. CODA is currently (January 1999) supported on the Solaris and Linux operating systems.
Data acquisiton system layout
In the 1970's early 1980's most data acquisition systems designed followed the pattern of a central hostmachine connected to a tree like structure, for example a CAMAC branch highway or FASTBUS segment interconnect, the leaves on which were digitising electronics. There was very little processing power outside the central host. The introduction of the microprocessor lead to increasing embedded processing power outside the central host. The data acquisition architecture was still relatively unmodified the central host pulled data from the front end systems. In the mid 1980's a new architecture emerged in which much more of the processing power was in the embedded processors which pushed data downstream. The push architecture lead to the development of the shared memory event builder. In this system the embedded processors have direct interfaces to a memory area which is shared between all the embedded processors and the host machine. The embedded controllers push data into the memory and the host pulls it out in the correct sequence to generate complete events.
Historical noteThe first design of a data acquisition system for the CLAS detector took the form of embedded FASTBUS processors interfaced to a shared memory event builder.
The problem with this architecture was that much of the hardware and all of the software was usually custom designed. This was time consuming and costly.
Sometime in the late 1980'2 early 1990's several groups started work on the same idea. Commercial network hardware was approaching the data bandwidth of the custom build datalinks used for data acquisition at a much lower cost. Also high speed network switches were being designed for the telecomunications industry which looked amazingly similar in function to the shared memory event builder. The idea was to link the embedded controllers to a commercial network switch which could then be linked to one, or more, host machines. Essentially the network switch would take the place of the custom built event builder. This model was chosen for CODA since it has several clear advantages over other models including, low cost, ease of maintainance, scalability, ease of upgrade.
CODA follows a model where a data acquisition system is composed of distributed heterogenous processors connected by a network. The first systems transfered data over 10 Mbit/S Ethernet, Hall C installed FDDI and achieved 30Mbit/S. There was a breif period where ATM was investigated for hall B but this medium was overtaken by 100Mbit/S Ethernet and was to costly to implement on a large scale. As of fall 1998 all major DAQ systems at Jefferson lab were using 100Mbit/S Ethernet. The CLAS detector uses four 100Mbit/S links in parallel for a sustained transfer of over 11Mbyte/S. (the limiting factor here is the RAID disk drive used to buffer the data on the host machine).
In coda the embedded processors can be in CAMAC, FASTBUS or VME. The CODA software is designed to
be extremely portable however as of Jabuary 1999 the only real-time operating system supported on the embedded controllers is VxWorks. CODA has been ported to linux but as of January 1999 we have not yet tested
real time Linux for embedded processors. We are also investigating LynxOS.
In CODA a hierachy of processes manipulate the flow of data from the detector to a storage device. Fore Example:
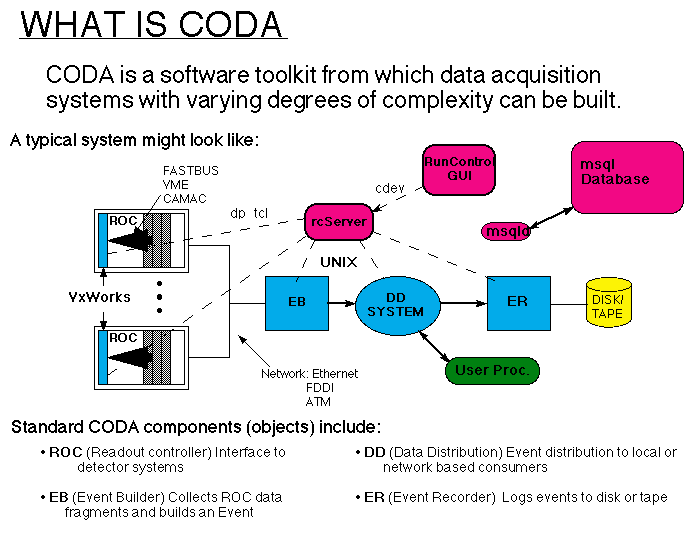
A typical small data acquisition system could look like...
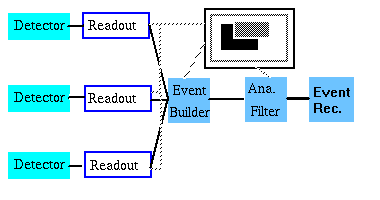
Here different components of a detector are read out by embedded controllers ("Readout Controllers" or "ROCs"). The data is buffered in the controller and when enough data has accumulated it is transmitted over the network. The buffering in the controllers is critical to reducing the overhead required to run a commercial network protocol such as TCP/IP. When running at low data rate CODA switches into a less efficient method of data transmission where events are passed over the network one at a time.
Since the data for a particular event is spread over data streams from several embedded controllers it is necessary to merge the data streams. This function is performed by the "Event Builder" (EB) which caches incoming buffers of events from the different controllers then merges the data streams in such a way that data which was taken concurrently in time (i.e. belongs to the same "event" in the detector) appears together. The event builder also formats the outgoing data stream and provides some measure of flow control to incoming and outgoing data.
The event builder in CODA is a software event builder runs as a UNIX process and inserts formatted events into a burrer manager called the "data distirbution system" (DD). The DD system uses UNIX shared memory protected by inter process semaphores to allow many processes access to the same events for analysis, filtering, monitoring, display etc.
The data distribution system may be configured to direct the data stream to an event recorder process which stores the events in a format of the user's choice. In contrast to other data acquisition software suites CODA does not have the capability to write tapes directly. The philosophy is that data will be written to high speed RAID disk arrays and archived to tape by commercially availible software such as OSM. For example hall B data will be written to a RAID array backed up by the computer center to a StorageTek tape silo.
The event builder and event recorder are designed so that they are relatively independent of the event format. There is a default CODA data format but the user can supply shared libraries for the event builder and event recorder which generate and write events in any format. For example halls A and C use CODA format which hall B (CLAS) use BOS and FPACK.
Clearly a CODA system can become complex and therfore difficult to control and monitor due to its distributed nature. Several tools are availible to make these tasks easier:
