JEFFERSON LAB SEARCH
-

Jefferson Lab operates large clusters of computers for Lattice Quantum Chromodynamics (LQCD), as part of the Nuclear and Particle Physics LQCD Computing Initiative (NPPLCI) established by the DOE Office of Science.
Their mission is to extend the fundamental understanding of nucleons and their quark constituents and to provide essential dedicated computing capability for critical nuclear theory calculations that are complementary to its experimental program.
Time on these clusters is scheduled by the USQCD collaboration, complementing the resources deployed at the DOE and NSF supercomputing centers.
The web pages on this site will provide you information on accessing and using the Jlab LQCD compute and storage resources. If you have additional questions or need help please use the SUPPORT button on the top right hand corner.
 User Accounts
User AccountsUSQCD collaboration users who need access to the Jlab LQCD compute and storage resources should apply for a new computer account and complete required training. For users that wish to reestablish an expired computer account you will complete the same steps as a new computer account. This new user account request section details the steps one needs to follow to get a computer account. We have compiled a list of new user frequently asked questions here.
 My Usage Metrics
My Usage MetricsThe Jlab cluster status web pages provide up to date information on your compute and storage usage besides a live cluster status display. Your usage against time allocated on the clusters and filesystem usage reports for work, volatile and cache. If you cannot find metrics of interest to you please use the SUPPORT button on the top right hand corner.
 Software
SoftwareInformation on submitting jobs through SLURM. Example run scripts for the various clusters. Information on modules, a tool that simplifies shell initialization and lets users easily modify their environment during a session using modulefiles.
 Hardware
HardwareList of Jlab LQCD clusters with detailed hardware configuration and performance metrics. Individual cluster hardware information -> 24s, 21g, 19g, 18p, 16p
 Frequently Asked Questions
Frequently Asked QuestionsThe "Frequently Asked Questions" (FAQs) section is a concise collection of common inquiries and answers about various topics. It helps users quickly find information and clarifies common doubts or concerns. We hope the compiled FAQs enhance your user experience by addressing common questions proactively and providing immediate, accessible answers.
-
jnfslk nflk gnfdlgd
NEW POLICY - PLEASE READ!!!! fgsdf sdfsdfsdf sdf sd fsdf fgdf fd gdf gdf

- sd mvnw vnwdfovn wfvnnl vw nov wov
- no vnowsd mvnw vnwdfovn wfvnnl vw nov w
- ovno vnowsd mvnw vnwd
- fovn wfvnnl vw nov wovno vnowsd m
- vnw vnwdfovn wfvnnl vw nov
- wovno vnowsd mvnw vnwdfov
- n wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw
- nov wovno vn
- owsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnow
erterter tret ert er ter t
sfgdg dfg dfgdfg dfgdfg dfgdfgdfgff gdfgdfg dfgdfg dfgdfg dfgdf dfgdfg sd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vno
gertgertretertertert et ret ert
kjhkjhkjhkjhkjhk njh hhn fh gdhgf h
sd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnowsd mvnw vnwdfovn wfvnnl vw nov wovno vnow
- Femtocenter.org website: maintenance and updates to standalone website. This includes added costs for security and platform updates. Work is verified by the webmaster and processed directly through JSA to the lab’s Drupal CMS contractor.
- HPDF website: maintenance and updates to standalone website. This includes added costs for security and platform updates. Work is verified by the webmaster and processed directly through HPDF to the lab’s Drupal CMS contractor
Web server support. Work with the CST division to maintain, update and upgrade existing file servers that interact with the lab’s websites. Submit Service Now tickets and follow up on them when web servers need upgrades or
- sd mvnw vnwdfovn wfvnnl vw nov wov
-
Thomas Jefferson National Accelerator Facility (Jefferson Lab) provides scientists worldwide the lab’s unique particle accelerator, known as the Continuous Electron Beam Accelerator Facility (CEBAF), to probe the most basic building blocks of matter by conducting research at the frontiers of nuclear physics (NP) and related disciplines. In addition, the lab capitalizes on its unique technologies and expertise to perform advanced computing and applied research with industry and university partners, and provides programs designed to help educate the next generation in science and technology.
Majority of computational science activities in Jefferson Lab focus on these areas : large scale and numerical intensive Lattice Quantum Chromodynamics (LQCD) calculations, modeling and simulation of accelerators and the experiment detectors, fast data acquisition and streaming data readout, high throughput computing for data analysis of experimental data, and large scale distributed data storage and management.
Many Jefferson Lab scientists and staffs lead or actively participate the computational efforts in the above areas. Among those are computer/computational scientists and computer professionals from newly formed computational sciences and technology division (CST), physicists from physics division and the Center for Theoretical and Computational Physics, and accelerator physicists from Center for Advanced Studies of Accelerators (CASA). In addition, collaborations with universities and industrial partners further research and development in computational science.
Jefferson Lab maintains various state of art high performance computing resources onsite. CSGF students will utilize these resources to carried out their researches in the specific areas described below:
Accelerator Modeling
CASA and Jefferson Lab SRF institute focus on advanced algorithms, such as fast multipole methods, for multiparticle accelerator dynamics simulations, artificial intelligence (AI) and machine learning (ML) applied to superconducting RF (SRF) accelerator operations, and integrated large and multi-scale modeling of SRF accelerator structures. These areas will be an essential part of a national strategy to optimize DOE operational facility investments, and to strengthen Jefferson Lab’s core competency of world-leading SRF advanced design and facility operations. Especially, current active simulation projects
like electron cooling, intra-beam scattering, and coherent synchrotron radiation present diverse research domains ranging from numerical algorithms development to parallel computing.
Streaming Data Readout
With tremendous advancement in micro-electronics and computing technologies in the last decade, many nuclear physics and high-energy physics experiments are taking advantage of these developments by upgrading their existing triggered data acquisition to a streaming readout model (SRO) , whereby detectors are continuously read out in parallel streams of data. An SRO system, which could handle up to 100 Gb/s data throughput, provides a pipelined data analysis model to nuclear physics experiments where data are analyzed and processed in near real-time fashion. Jefferson Lab is leading a collaborative research and development effort to devise SRO systems not only for CEBAF 12GeV experiments but also for the upcoming EIC facility. SRO development offers CSGF students some exciting research areas such as network protocol design, high speed data communication, high performance data compression and distributed computing.
Physics Data Analysis
Analysis of data from modern particle physics experiments uses technically advanced programming and computing techniques to handle the large volumes of data. One not only needs to understand aspects of parallel programming using modern languages such as C/C++, Java, and Python, but also must incorporate knowledge of experimental techniques involving error propagation and estimation in order to properly interpret the results. Aspects of this range from writing a single algorithm used in event reconstruction, to using the collection of algorithms written by others, to managing campaigns at HPC facilities that apply these algorithms to large datasets. Detector calibrations and final physics analysis are also significant parts of the analysis chain. CSGF students could participate in any of these areas.
Machine Learning
Rapid developments in hardware computational power and an ever increasing set of data has lead to explosive growth in machine learning techniques, specifically deep learning techniques. These techniques threaten to change just about every facet of modern life and nuclear physics is no exception. At Jefferson Lab machine learning is being developed for every step in the physics workflow. To deliver beam to the experimental halls the accelerator relies on radio frequency (RF) cavities to accelerate the electrons. Occasionally these cavities, of which there are over 400 in operation around the accelerator, fault which disrupts the delivery of the beam to experiments. To quickly identify and diagnose cavity faults A.I. is being developed and deployed. Experiments themselves are developing and/or deploying A.I. to monitor detector performance, decide what data to keep, reconstruct detector responses, simulate the detectors, and even to analyze collected data. With the active development of machine learning tools and techniques Jefferson Lab hopes to drive nuclear physics research forward, enabling physicists to more quickly obtain and analyze high quality data.
-
coming soon

-
Computational Sciences and Technology (CST) Division
-
If the list of FAQ's does not answer your question then please submit your question using this support form https://lqcd.jlab.org/lqcd/support
- Can you point me to instructions to set up MFA (2-factor authentication) for the login gateway login.jlab.org?
- Do you have a way to transfer files using Globus?
- Do you have a way to transfer files other than Globus?
- How do I renew my expired JLab computer account?
- How do I change my JLab Common User Account (CUE) password?
- What partition/queue should I use?
- Is there a "debug" queue I can use for a quick turn around on my test jobs?
- What is the default MPI?
- How can I request KNL nodes booted in flat-quad mode?
- How can I explicitly request 18p or 16p nodes?
- What is the USQCD allocation jeopardy policy?
- I do not see CUDA on the cluster login nodes?
- I need to launch a bunch of single GPU jobs on 21g. Is there any way to run multiple instances of those single GPU jobs on a single node?
- How do I transfer source tarballs to the cluster login nodes as some sites seem to be blocked?
- I had a previous Jefferson Lab account which is now disabled. How do I reestablish the account again?
1: Can you point me to instructions to set up MFA (2-factor authentication) for the login gateway login.jlab.org?You will need to setup one of the following MFA software tokens Google Authenticator or MobilePASS / MobilePASS+ to be able to authenticate with MFA.
2: Do you have a way to transfer files using Globus?Yes we do. More information on this is available here.
3: Do you have a way to transfer files other than Globus?You can use SCP to transfer files but it requires setting up a way to automate the 2-hop login process for users that are not on the JLab network or not using a VPN. More information on this is available here.
4: How do I renew my expired JLab computer account?IF you had a computer account at JLab in the past then please verify this by searching your information in the JLab phone book.
- If an entry for you exists in the phone book, then the quickest turn around on this request is by calling the JLab Computing Center Help Desk at (757) 269 7155 on weekdays between 8am to 4pm eastern time. You may also send them an email (slower response than a phone call) at helpdesk@jlab.org.
- If an entry for you does not exist in the phone book, then please follow the instructions as indicated here https://www.jlab.org/lqcd/user-accounts
5: How do I change my JLab Common User Account (CUE) password?You may use the web interface by logging in to the JLab Computer Center web site (https://cc.jlab.org) and clicking on the "Password Change Utility" link in the "Utilities" section.
If you get an ERROR when attempting to change your password, please contact the IT Division Helpdesk (email: helpdesk@jlab.org or phone: 757-269-7155).
6: What partition/queue should I use?For an up-to-date partition list please see the following web page.
7: Is there a "debug" queue I can use for a quick turn around on my test jobs?One has to use the "debug" QoS when submitting jobs that require a quick turnaround. More information about the QoSes is available under section "SLURM QoS (Quality of Service)" at -> https://www.jlab.org/lqcd/software/slurm
8: What is the default MPI?Right now, there is no default MPI configured in SLURM. The following command will list APIs srun supports for MPI.
$ srun --mpi=list MPI plugin types are... ...
9: How can I request KNL nodes booted in flat-quad mode?Use the '--constraint=flat,quad' or '-Cflat,quad' option to request nodes in flat-quad mode. If there are insufficient nodes available, SLURM will reboot nodes into the requested mode. Similarly, if a user needs cache-quad mode, they must use '--constraint=cache,quad' or '-Ccache,quad'.
10: How can I explicitly request 18p or 16p nodes?Use '--constraint=cache,quad,18p' or '-Ccache,quad,18p' option to request 18p nodes in cache-quad mode. Similarly, use '--constraint=flat,quad,18p' or '-Cflat,quad,18p' option to request 18p nodes in flat-quad mode. To request 16p nodes, replace 18p with 16p in the before mentioned options.
11: What is the USQCD allocation jeopardy policy?The latest USQCD jeopardy policy is on this web page.
12: I do not see CUDA on the cluster login nodes?To compile your code using CUDA, on the cluster login nodes (qcdi1401 or qcdi1402) check available CUDA versions as follows:
[@qcdi1402 ~]$ module use /dist/modulefiles/ [@qcdi1402 ~]$ module avail ----------------------------------------------------------- /dist/modulefiles/ ----------------------------------------------------------- anaconda2/4.4.0 anaconda3/5.2.0 cmake/3.21.1 curl/7.59 gcc/7.1.0 gcc/8.4.0 go/1.15.4 anaconda2/5.2.0 cmake/3.17.5 cuda/10.0 gcc/10.2.0 gcc/7.2.0 gcc/9.3.0 singularity/2.3.1 anaconda3/4.4.0 cmake/3.18.4 cuda/9.0 gcc/5.3.0 gcc/7.5.0 go/1.13.5 singularity/3.6.4 ------------------------------------------------------------ /etc/modulefiles ------------------------------------------------------------ anaconda ansys18 gcc_4.6.3 gcc-4.9.2 gcc-6.2.0 gsl-1.15 mvapich2-1.8 anaconda2 ansys2020r1 gcc-4.6.3 gcc_5.2.0 gcc-6.3.0 hdf5-1.8.12 mvapich2-2.1 ......
Load the desired CUDA version as follows:
[@qcdi1402 ~]$ module load cuda/10.0
Additional modules related documentation is available here https://jlab.servicenowservices.com/kb_view.do?sysparm_article=KB0015353
13: I need to launch a bunch of single GPU jobs on 21g. Is there any way to run multiple instances of those single GPU jobs on a single node?There is no way to just reserve a single gpu on 21g. You must run 8 separate programs (without the srun) with each run configured to "see" a different gpu. That can be accomplished by setting ROCR_VISIBLE_DEVICES for each srun properly as shown by an example below:
!/bin/bash #SBATCH --nodes=1 #SBATCH -p 21g export OMP_NUM_THREADS=16 ROCR_VISIBLE_DEVICES=0 ./mybinary & ROCR_VISIBLE_DEVICES=1 ./mybinary & ROCR_VISIBLE_DEVICES=2 ./mybinary & ROCR_VISIBLE_DEVICES=3 ./mybinary & ROCR_VISIBLE_DEVICES=4 ./mybinary & ROCR_VISIBLE_DEVICES=5 ./mybinary & ROCR_VISIBLE_DEVICES=6 ./mybinary & ROCR_VISIBLE_DEVICES=7 ./mybinary & wait
14: How do I transfer source tarballs to the cluster login nodes as some sites seem to be blocked?The blocking of certain remote sites from the cluster login nodes is a mitigation strategy implemented by the JLab Computer Security team. While we cannot circumvent this blockade, we recommend that something like this should work in most cases.
Example of a failing command run on cluster log node:
[@qcdi2001 ~]$ wget https://support.hdfgroup.org/ftp/HDF5/releases/hdf5-1.10/hdf5-1.10.8/src... --2022-02-28 13:10:01-- https://support.hdfgroup.org/ftp/HDF5/releases/hdf5-1.10/hdf5-1.10.8/src... Resolving support.hdfgroup.org (support.hdfgroup.org)... 50.28.50.143 Connecting to support.hdfgroup.org (support.hdfgroup.org)|50.28.50.143|:443... connected. HTTP request sent, awaiting response... 503 Service Unavailable 2022-02-28 13:10:01 ERROR 503: Service Unavailable.
Recommended option for a successful execution of the above command:
[@qcdi2001 ~]$ ssh jlabl5 curl https://support.hdfgroup.org/ftp/HDF5/releases/hdf5-1.10/hdf5-1.10.8/src... > hdf5-1.10.8.tar.bz2
15: I had a previous Jefferson Lab account which is now disabled. How do I reestablish the account again?If you previously had a computer account that has since expired, you must submit a new registration form by following the steps outlined below. Be sure to indicate on the form that you need a new computer account, and under 'Requested Username,' request your old username. If JLab IT still has your old username on file, they will restore it. If the old username is no longer available, as noted in Step 3 below, we will associate your new username with the appropriate UNIX groups. Here is the link to submit a new registration: https://misportal.jlab.org/jlabAccess/
Detailed information about a new account request is here -> https://www.jlab.org/lqcd/user-accounts
-
These SRM "Storage Resource Manager" utilities can query the status of or move files between disk and tape, preserving the files canonical name; i.e. the file has the same name (path) on tape and on disk.
srmProjectInfo projectName get project information specified by projectName, information includes project quota, pin quota, available pin quota, etc. srmGet [-t life_time] [-e email] file_path_1 file_path_2 ... srmGet [-t life_time] [-e email] [-r] directory_path get file(s) from tape system to cache disk -t lifetime to specify the life time of file pinned (default is 10 days) -e email to request cacheManager to send email when all files in srmGet finish. -r recursively get all files under a named directory (recursive will only go one level) srmPut [-d] file_path_1 file_path_2 ... srmPut [-d] -r directory_path put file(s) with size larger than 1 MB into the tape silo system (without waiting the normal time delay). -r recursively get all files under a named directory (recursive will only go one level) -d delete the files after they have been put on tape (frees space faster) srmPin [-t lifetime] cache_file_path1 cache_file_path2 srmPin [-r] [-t lifetime] cache_dir_path1 Pin or mark a file or files in a given directory as in use and not to be deleted -r recursive -t life_time set the lifetime for the pin srmPinStatus [-l] list the pin status of given file(s) -l long format srmRequest request_id1 request_id2 ... get status information of srmGet/srmPut request(s) srmCancel request_id1 request_id2 ... cancel request(s) specified by request-id srmPendingRequest [user] list all pending and active request(s) submitted by this user or a given user srmDupilcatedFile [user] list all duplicated file create by this user or a given user srmTapeRemove path1 path2 ... remove given files (not directory) from tape library (files are marked deleted and will not be copied on a subsequent tape compress).NOTE: When using tapeRemove for the first time, you must get a Jlab certificate. Please reference this page on how to get a new certificate. Finally please SCP the file .scicomp/keystore to qcdi (or the associated login node for a cluster)
srmChecksum path1 get the crc32 checksum of a given file already on disk; this checksum is used by Jasmine system to verify data integrity on read from tape (all files in the Jasmine tape system have a crc32 checksum value stored in its stub file). srmLs [options] cache_path1 cache_path2 cache_path3 .... list file properties (cacheManager related meta data; details on next page)
srmLs explained
Name
srmLs - list file properties (cacheManager related meta data)
Syntax
srmLs cache_path1 cache_path2 cache_path3 ....
srmLs [options] cache_directory_path
Description
If no argument is given, lists all larger files on tape but not on disk, owned by this user. Otherwise lists files in a given directory.
Parameters
cache_path: The full path of a file on cache disk, it should start as /qcd/cache/... Wild cards in the file name are supported. When using a wild card, path must be quoted and add backslash \ before * and the wild card must in the file name and not in the path directory.
Options
[-h] or [--help] - to display the usage and exit.
[-l] - to show long list including group and modification time.
[--cache] - to list only the files in the cache
[--ncache] - to list only the file not in the cache
[--silo] - to list only the file on tape
[--nsilo] - to list only the file not on tape
[--pin] - to list only the file pinned
[--unpin] - to list only the file not on tapeNotes
Options [--cache], [--ncache],[--silo], [--nsilo], [--pin], [--unpin] can be used together. Any combination of the options is equivalent to an "AND" operation. For examples, with [--ncache] and [--silo] options only the files on tape and not on disk will be listed. A file larger than 2MB is defined as a large file, files smaller than 2MB will not be backed up to the tape system and are not reported by the srmLs utility.
Examples
- Get summary information:
%srmLs - print the summary information of the files owned by this user.
- List file properties:
%srmLs /qcd/cache/LHPC/NF0/aniso/test/foo - print specified file properties, such as pin count, space type, size, etc.
- List some files' properties in a given cache directory:
%srmLs --silo /qcd/cache/LHPC/NF0/aniso/test - print the file which in tape system
- Get all files under a given directory into cache disk:
%srmLs --cache --nsilo /qcd/cache/LHPC/NF0/aniso/test - print the file which in cache disk but not in silo.
-
Each project is allocated space on the following shared storage resources which are visible from both cluster interactive and worker nodes:
Filesystem Description Backed Up High Quota Limit * Hardware /qcd/home Every user has a home directory.
Intended to store non-data files, such as scripts and executables.YES hard NetApp, via NFS /qcd/work Designed for project or group use. Limited size, project users managed area.
Intended to store software distributions and small data sets which don't need to be backed up.NO hard ZFS, via NFS /qcd/cache Write-thru cache to tape with auto-removal of the disk copy as needed.
Intended to store data files (input and output) for batch jobs.
/qcd/cache is implemented above a Lustre file system and semi-managed with automatic file migration to tape after some period, with eventual automatic file removal from disk. Check the "Automated Data Management Policies for /qcd/cache" section below for updated backup and deletion policies.YES soft Lustre, using ZFS OSD /qcd/volatile Auto-managed global scratch space (never full).
Intended to hold the output of one job that will later be consumed by a subsequent job. May also serve as an area to pack and unpack tar balls. In cases where users work with many small files in one directory this is the best place for that type of data. (Note that if the files need to persist on disk for a long time, /qcd/work is a good alternative) /qcd/volatile is implemented above a Lustre file system. Check the "Automated Data Management Policies for /qcd/volatile" section for updated deletion policies.NO soft Lustre, using ZFS OSD /scratch Local disk on each worker node. Suitable for writing all sorts of data created in a batch job. Any precious data needs to be copied from this area before a job ends since the area is automatically purged at the end of a job. NO None XFS Globus Globus End-Points named jlab#gw1 and jlab#gw2 which you can use to transfer data in and out of the above mentioned storage areas. Please refer to the documentation on globus.org on setting up a Globus Connect Personal if needed. More information about the JLab Globus endpoints is here. Instructions on using SCP to transfer data are available here. There are two types of thresholds within the quota systems, High Quota and Guarantee. Your quotas and current usage can be viewed through the cluster status portal under the File System menu:
* High Quota: this is a hard limit for /qcd/home and /qcd/work, and a soft limit for /qcd/cache and /qcd/volatile; a write to /qcd/cache or /qcd/volatile will always succeed, but afterwards, older files will be deleted if you are over your quota, enforced by the in-house processes a few times a day.
Guarantee: this is not oversubscribed, and so you will always have at least this much space available to your project.
If a directory does not exist for your project under any of the above-mentioned filesystems, you may request one. If your quota is too small, you may request a larger quota limited by the remaining available space. Quotas are oversubscribed, so projects cannot all use their full quota concurrently.
Automated Data Management Policies for /qcd/cache
When a project is over their High Quota limit the following data backup and deletion policies will be enforced.
/qcd/cache Backup policy:
The files which satisfy the criterion size between 3MB to 1TB and 12 days old will be automatically copied to tape.
/qcd/cache Deletion policy:
Oldest files which satisfy the criterion pin count = 0 AND backed up = Yes will be deleted.
Note: Small files are not written to tape and deleted but there is a soft limit of 1 million files per user. We strongly recommend users store only large permanent files under /qcd/cache. If a project generates a lot of small files, please put them under /qcd/work or /qcd/volatile disk areas.
Automated Data Management Policies for /qcd/volatile
The /qcd/volatile area is managed by an automated process that cleans up periodically in multiple steps as listed below. In the rules mentioned below the target threshold is defined as the "aggregate used space by all projects".
- All files that have not been used for more than 6 months will be deleted.
- If a project exceeds its quota and the target threshold is exceeded (>75%), the least-recently-used (LRU) files will be deleted until the total usage of the project is below their High Quota and the target threshold is met (<75%).
- If the target threshold is exceeded and reaches a critical point, additional aggressive file deletions may be performed using the rule mentioned in #2.
-
NOTE FOR USERS WITH EXPIRED USER ACCOUNTS: If you previously had a computer account that has since expired, you must submit a new registration form by following the steps outlined below. Be sure to indicate on the form that you need a new computer account, and under 'Requested Username,' request your old username (see a sample screenshot of the input here). If JLab IT still has your old username on file, they will restore it. If the old username is no longer available, as noted in Step 3 below, we will associate your new username with the appropriate UNIX groups.
A member of the USQCD collaboration may request an account to access the Jlab LQCD clusters. Large allocations of time are allocated annually by the USQCD Scientific Program Committee. Small allocations such as class C may be requested from Amitoj Singh.
To request access to Jlab LQCD resources please follow the steps listed below. If you have questions or are stuck at any step of the process please use this help request form https://lqcd.jlab.org/lqcd/support or contact Helpdesk at (757) 269-7155 or email helpdesk@jlab.org
Step 1. Apply for a new Jlab Computer User Account
To get a Jlab user account, each new user must fill out an Access Registration form. Listed below are a few points to note when filling the form.
- Most users will select "Registration Type" as USER-REMOTE
- List Amitoj Singh as your Jlab sponsor
- As a reference, the following document https://www.jlab.org/facilities/steps-registration lists all available site access registration and user types
Fill out the Access Registration Form https://misportal.jlab.org/jlabAccess here.
Step 2. Take the Cyber Security Awareness (CST001) Training
Completion of this step is mandatory for Step 1. Complete the required training CST001 at https://www.jlab.org/div_dept/train/webbasedtraining.html
Step 3. Completing your account setup (UNIX groups and SLURM account)
At this point, you have a Jlab computer and LQCD cluster account. However, you still need access to the various file-systems and the SLURM account associated with your project.
- For file-system access and appropriate permissions, your user account must belong to the lattice UNIX group and to your project's UNIX group. Please use this form https://lqcd.jlab.org/lqcd/support to request access to file-system areas associated with your USQCD SPC allocated project. IF you are not sure about your project's UNIX group, please contact your PI first.
- In order to submit jobs to the SLURM batch system you will need to be added to the appropriate SLURM account associated with your USQCD SPC allocated project. A list of current SLURM accounts associated to USQCD projects is here https://lqcd.jlab.org/lqcd/clusterUsage/report. Once you have the information required please use this form https://lqcd.jlab.org/lqcd/support to request access to the SLURM account associated with your USQCD project.
Step 4. Setup your 2-factor (MFA) authentication token.
Mandated by the DOE, as of March 21 2023 ALL users must authenticate with 2-factor (MFA). You will need to setup one of the following MFA software tokens Google Authenticator or MobilePASS / MobilePASS+ to be able to authenticate with MFA. If you have any questions about this step use this help request form https://lqcd.jlab.org/lqcd/support
FINAL STEP. Accessing compute resources
You will need to first SSH to the 2-factor (MFA) authenticated gateway node, login.jlab.org using the 2-factor authentication mechanism as configured for your account. Then using your CUE password (not 2-factor MFA) SSH into one of the interactive login nodes as listed below:
- qcdi.jlab.org - access to 16p, 18p and 19g clusters
- qcdi2001.jlab.org OR qcdi2002.jlab.org - access to 21g cluster only
- qcdi24s.jlab.org - access to 24s cluster only
A common question asked by new users is how to transfer files over the 2-hop access procedure.You can use SCP to transfer files but it requires setting up a way to automate the 2-hop login process for users that are not on the JLab network or not using a VPN. More information on this is available here.
We have compiled a list of new user frequently asked questions here.

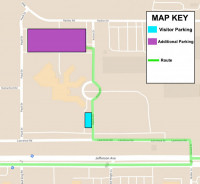
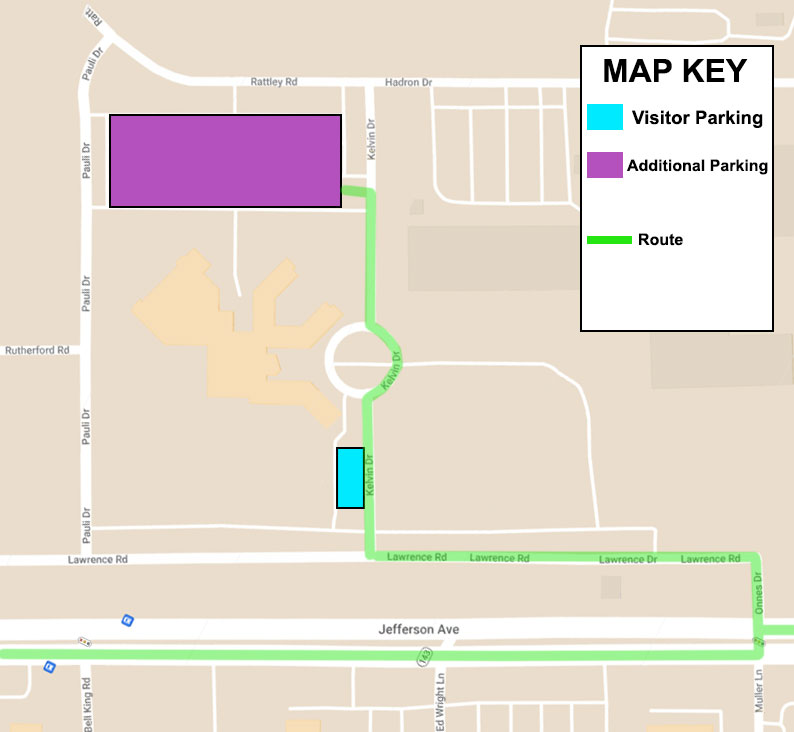
Figure 1. Jlab LQCD cluster hardware and file-system layout








{kind=link}
{kind=link}